Engram
An evolving-memory engine for AI agents — memory is authored at write-time and the current state is derived at read-time, so the agent answers from what's true now, not just what's similar.
[latest2026-06-10]83.2% on the full 100-episode MEME run — best published system: 42%.
Engram exists to surface the right memory, not merely the correct one.
Pitch
Engram exists because I live with this problem: I work alongside AI agents daily — a companion that accumulates memory across months, coding agents that share a store while they build — and their memory kept failing the same way: on-topic, confidently retrieved, and no longer true. The framework problem underneath is general. Agent memory ranks candidates by semantic similarity to the current query, which answers "what's relevant" and fails at "what's true now" — a store full of on-topic text can't tell the current value from the three values it replaced, a retracted fact from a live one, or a decision from discussion about the decision.
Engram moves the effort to the two places it pays. At write-time, an authoring agent shapes raw conversation into typed, dated, dependency-linked memories. At read-time, retrieval reads that shape and derives the live state — current, superseded, pending, or honestly uncertain. Similarity finds the neighborhood; provenance and shape decide what the agent actually gets. The scorecard above is that bet, measured.
The sixty-second version
The whole page in six lines — each one links to its long form.
- The problem is memory that won't hold still — philosophy: decisions over discussion was the seed; it generalized to currency, deletion, and dependency. You can't author the future, so derive it at read time.
- One local daemon, three thin clients — architecture: a FastAPI core owning the embedder and N stores, a 30-tool MCP adapter for agents, a dashboard mounted on the same port for operators.
- Files → raw → authored drawers — corpus: the typed substrate lives in the third tier, written by an authoring agent whose prompt is treated as a versioned, benchmarked artifact.
- One search, routed by the shape of its hits — recall: deletion, cascade, and absence are derived states, never stored; scoring ranks candidates inside the pool with six dampening-aware signals.
- The proof is external — benchmarks: 83.2% on MEME vs 42% for the best published system, separation entirely on the evolving-memory tasks; 1,000+ tests and the honesty disciplines in methodology underneath.
- The history is self-hosted — decisions: ten pivots from April to June, reconstructed from Engram's own store.
Philosophy
Why provenance discriminates, how the thesis grew teeth, and the bounded claim that follows.
Right is not a label you can attach to a
(query, drawer)pair in advance. It's only evaluable at the agent-response or task-outcome level.
The thesis
Decisions over discussion. When two memories on the same topic compete, the authoritative one should win — regardless of which is fresher, or which is closer to the query's vocabulary. Provenance is the discriminator.
That was the seed claim, and it generalized. "The architect's decision beats the engineer's notes" is one instance of a bigger problem: memory doesn't hold still. Values get superseded, facts get retracted, one thing quietly depends on another that changed. A similarity search returns the current value and the three values it replaced, all equally on-topic, with no way to tell them apart. The general form of the thesis:
- You can't author the future. When a memory is written, nobody knows it will later be superseded — so the system never stores "this is current" or "this is stale." It stores the forward-knowable ingredients: what kind of claim this is, when it was made, what it depends on.
- So derive it at read-time. Retrieval reads the typed, dated trail and computes the live state — current, superseded, pending, or honestly unknown. The store never contains the word "uncertain"; it derives uncertainty from the shape of what it does contain.
Authority, supersession, deletion, and dependency are all the same move: provenance metadata doing the work similarity can't.
What "right" means
Right and correct are different problems. A correct retrieval surfaces something relevant. A right retrieval surfaces something the agent can build on without subtle drift. Five properties: situational (planning and debugging want different things from the same pool), provenance-aware (who said it matters), supersession-aware (newer doesn't mean truer — and neither does older), silence-tolerant (an empty result can be the right answer), and goal-serving (there's no static (query, drawer) → label).
Why similarity-only misleads
An agent asks: "what's the architecture of this system?"
Vector retrieval returns everything semantically close — the architect's decision, the engineer's workaround notes, three diary entries discussing architecture. All on-topic. Only one is right. If the agent consumes the top-k mixed set, it fabricates a synthesis where the architect's voice is one tile in a mosaic instead of the authoritative source. The user never sees the drift — they see an agent that "knew" about their project and still produced something subtly off.
I caught this happening in a session about Engram itself: the design conversation drifted from authority-supersession into temporal-supersession — the wrong axis — without either participant noticing for a stretch. The dated entry, with the in-the-moment quote, lives in decisions.
The evolving-memory cases are the same failure with the stakes raised. Ask "what medication am I on?" against a store holding three answers from three months, and a similarity-ranked reader is wrong whenever the freshest text isn't the truest — which is exactly when it matters.
Both ends are agents
In deployment, the thing writing to Engram is an AI agent. So is the thing reading from it. They share an embedder's vocabulary distribution by construction — so vocabulary coupling between author-side and reader-side isn't a discipline the system has to enforce; it's a structural property of the deployment. The author preserves the user's idioms because the embedder will need them at retrieval; the reader trusts the author wasn't paraphrasing.
The same structure is why memories are written as vision and guide, not commands — the reading agent applies them with judgment — and why the context rule is precision, not volume: top of mind, not more of mind. Enough context to do the job, never so much the goal gets lost. It's also how Engram itself was built — the same write-with-intent, read-with-judgment shape it's designed to support; methodology covers that collaboration.
The bounded claim
I want to be specific about what's being claimed.
Engram is an evolving-memory engine for AI-to-AI memory: agents author typed, dated, provenance-tagged memories at write-time, and retrieval derives the current state at read-time — on lightweight local infrastructure. Within that regime it's the best architectural fit I know of, and the benchmarks section puts numbers on it. Outside it — pure user-authored memory, RAG over arbitrary documents, scenarios where similarity is the goal — Engram degrades to hybrid retrieval with no distinctive advantage. Which is fine, but not the thesis.
Architecture
One HTTP API, three thin clients, a daemon at the center.
One HTTP API. Three clients. The daemon is the canonical implementation; the MCP adapter, the dashboard SPA, and operator tooling are thin translators.
The discipline
Engram is built on one constraint: one HTTP API, three clients. The daemon implements; the MCP adapter, the dashboard SPA, and any operator tooling all speak to the same surface. No client-side caching, no second source of truth, no semantic branch points. When behavior changes, it changes in one place.
The daemon
src/engram_daemon/ owns the FastAPI HTTP API, the in-process embedder, the multi-tenant StoreRegistry, the dashboard mount at /dashboard/*, and a job runner for async work (imports, source sync, authoring batches). It refuses to spawn beside another instance, persists which stores were open across restarts (replay is fail-open — missing paths log and skip; a malformed registry file gets renamed, never crashes startup), and reads bearer tokens from ~/.engram/auth.json in three tiers — read, write, admin.
Tiers govern write scope — what types each may author, what context each receives — not retrieval weight. Authority in scoring lives on the type of claim, not the claimant.
MCP adapter — what agents use
src/engram_mcp/ is a stateless stdio bridge. Agents spawn it as a child process; it translates tool calls into HTTP against the daemon, probing /healthz at boot and failing soft if the daemon isn't there — detect-and-attach, never lifecycle management. It holds no embedder, no Chroma connection, no Store handle: the previous era of in-process MCP servers had each agent loading its own embedder and contending for the same Chroma lock, and the adapter pattern eliminated both. It currently surfaces 30 tools — search and recall, drawer authoring, source ingestion, raw-memory expansion, store management — all HTTP shims with Pydantic validation at the boundary.
Dashboard — what operators use
dashboard/ is React 18 + Vite + TanStack, mounted by the daemon at /dashboard/* and typed from the daemon's /openapi.json — so the dashboard and the adapter cannot drift. Operator and agent see the same store, exactly. The dashboard section tours it.
Embedder
The default is Qwen3-Embedding-0.6B — 1024-dim, in-process, Apache-2.0, last-token pooled with an asymmetric query instruction (queries and passages embed differently, which is what a retrieval-tuned model buys over a general one).
It's the third embedder the project has run, and the criteria that picked it are the same ones that retired its predecessors: in-process beats external serving, a permissive license is non-negotiable, and parity-or-better on Engram's own retrieval workload decides ties. A migration CLI re-embeds existing stores across swaps; a mismatch guard refuses to open a store against the wrong embedder rather than silently degrade. An Ollama-served option survives behind ENGRAM_EMBEDDER=ollama, and GPU remains the discipline — CPU runs require an explicit opt-in. The swap history, with dates and the opinions that aged out of it, lives in decisions.
Stores — handles, not god-classes
Each store is a directory on disk: metadata, a single-writer/multi-reader lock, three Chroma collections, and a SQLite FTS5 keyword index. The Store class is a handle — connections and paths, no logic — with operations as free functions in engram/ops/, each taking Store as the first argument, and Pydantic models as the single source of truth across HTTP / MCP / internal calls. This ended the god-class era: the monolithic 4,052-line EngramService and its module-level globals gave way to a shape where multi-store operation is safe and every operation is independently testable.
Two deployments, one engine
A store carries a deployment field — default (multi-agent) or companion — and that one field is the whole mode switch. Same daemon, same Store handle, same retrieval path; what swaps is the cast:
- Multi-agent targets orchestration runtimes — named agents writing into shared memory, queries that resolve to the canonical answer. Type library: the engineering work-artifact vocabulary (
architecture,decision,bug,directive, …). - Companion targets one agent, one human, accumulating memory over time — the shape my Mantle companion deployment lives in. Four speech-act types —
want/preference/opinion/observation— and retrieval returns a set to compose from, not a single winner: no single memory is the answer; the narrative is the answer.
Because the switch is per-store, one daemon hosts both shapes simultaneously. Neither is a fork of the other — and the rest of the page covers what's stored (corpus), how it's written (authoring), and how a query becomes an answer (recall, scoring).
Corpus
Three tiers, two transformations, one durable substrate.
Files are the durable first tier. Raw memories and authored drawers are derivations of them.
The three tiers
A store holds three tiers, each a derivation of the one above:
- Files — durable, foldered, SHA256-deduped. The user's organized substrate, in
<store>/_corpus/on disk. (The directory used to be called_ingest_staging/— the rename was the decision: files stopped being throwaway chunker input and became a corpus operators reorganize, walk back through, and re-ingest when authoring discipline improves.) - Raw memories — unframed chunks in
engram_raw_memories. Two paths in: file ingest (the chunker dispatches by detected type — markdown by heading, JSONL by line, PDF by page — each chunk carrying an origin back-pointer for citation) and direct add from a conversation or session. Retrieval is similarity-only, and agents expand into specific chunks on demand: the framed drawer is the primary surface; the verbatim record is one tool call away. - Authored drawers — framed, typed memories in
engram_drawers: the pool retrieval scores, routes, and derives state from. Produced by the authoring pipeline from raw sessions, or written directly — and always hard-linked back to the raw chunks they derive from.
Pool separation as structure
Files have no path into the drawer pool that skips raw. The boundary lives at the transformation — the raw → drawer step is where the authoring agent decides what the framed claim should be — and holding the tiers separate makes it architectural, not policy: code chunks and decision drawers never compete for the same ranked slot, because the pool isn't shared.
Wings, rooms, drawers
The data model under engram_drawers is three orthogonal axes: wing (life-domain category — projects, philosophy; stable enough to still mean something after disuse), room (persistent identity within a wing — projects/rev-engram; not a topic, not a session), and drawer (the atomic memory unit, retrievable in isolation). Topic stays a free per-drawer tag.
Anatomy of a drawer
The metadata is what the read side operates on:
memory_type— categorical claim (decision,directive,want, …); type × intent drives the scoring multipliermemory_shape— what kind of fact this is (stable_fact,evolving_attribute,contingent_value,conditional_value,retraction, …); the field recall routing readsthread_label/depends_on— the slot an evolving value lives on, and the upstream it's set by; together they make dated trails and dependency walks possiblesignature— distinctive verbatim phrase, opt-in, indexed by FTS5 for exact dispatchpin_status— explicit authority that survives recency decaysalience— decay-with-feedback (2.5%/week down, bumps on use)wing/room/topic, andderived_from— placement and walkback
What happens to these fields at read time is the recall and scoring story.
A note on source chunks
A fourth collection — engram_source_chunks — serves a parallel, similarity-only retrieval surface for code and doc reference material (engram_search_source). Different use case, deliberately off the three-tier pipeline: source chunks never enter the drawer pool, and sync reconciles by content hash so only changed chunks re-embed.
Recall
One-shot recall over a memory that won't hold still — one search, routed by the shape of its hits.
The store never stores "current." It never stores "uncertain." It stores a typed, dated trail — and derives the rest, one question at a time.
The problem
Imagine a memory that has to answer in one shot. A question comes in, the system gets exactly one retrieval to surface context, and whatever it surfaces is the entire basis for the answer. No second look, no agent drilling back through history.
Now make the facts move. The user's medication changes. A project's database gets swapped. A value that depended on something else goes stale when that something else changes. A thing gets deleted and should never be spoken of again. Sometimes the honest answer is "I'm not sure anymore."
A plain similarity search can't do this. It returns whatever text looks most like the question — three superseded values and the current one, indistinguishable. The reader picks one and is wrong a third of the time. Engram's whole game is doing better than that, in one shot.
The bet: shape it at write-time, decide it at read-time
Two ideas carry everything. Author for retrieval: when a conversation ends, an authoring pass writes typed, structured memories — what kind of fact, what it depends on, when it was recorded, what area it belongs to. The expensive thinking happens once, at write time. And you can't author the future, so derive it: a memory can't know it will later be superseded, so the system never stores "current" or "stale" — it stores the forward-knowable ingredients and computes the live state at read time by walking the trail in order.
The query returns the question
Engram doesn't parse the question's words to classify it — embedding models are surprisingly bad at telling "what is my X now" from "list my X over time"; the vectors are nearly identical. Instead it runs one search and reads the shape of what comes back. The hits themselves say what kind of question this is.
Did the top hit land on a deep thread — an entity with history — or carry a dependency on something else? Then this is an evolution question. Otherwise it's semantic: a stable fact or a set of them, and within that, either one hit towers over the rest (a single exact answer) or the field is flat (many facets of one area).
One deliberate exception: a query that declares its own shape wins over hit-shape inference. "Tell me everything about…" demands the wide gather even when one hit towers; "list X over time" stays on the trail because the history is the answer; "recite the exact…" wants one artifact and never a gather. The declaration binds every downstream shape decision — a rule that was learned by measurement, not by design taste.
The evolution route — reading a dated trail
When a question lands on an entity that changed (or depends on one that did), Engram reconstructs the narrative trail — every value that slot has held, in chronological order, each tagged with its shape — then reads the trail and picks one of three regimes. It's one algorithm with three outcomes.
Deletion — don't recite what was removed. "What's my partner's name?" — but the relationship ended. The latest drawer on the thread is a retraction, so the answer isn't a name; it's "that's no longer recorded." The old value is suppressed entirely.
Cascade — promote the value that was waiting. The answer exists in no single drawer; it has to be assembled from facts the store holds separately — and a literal one-shot reader won't do that on its own, so Engram does it:
The key move is that the replacement value was stated in the rule when the user first said it, so the author captured it into a typed consequent_value field at write time. The read just promotes it once the trigger fires — no guessing, no re-parsing prose.
Absence — derive "I don't know." A value rested on something that changed, and nothing new was ever declared. Three conditions, none of which is the answer by itself: the value is contingent, its basis moved later, and no replacement exists. contingent + basis-moved + no-replacement → uncertain — and the render shows its work: "Last recorded: X, determined by Y. Then Y resolved. No replacement was recorded, so the previous value no longer holds." That's just how memory should work.
One hard-won subtlety underneath all three: labels drift; entities persist. A weak author can't keep one entity on one label across sessions — the upstream gets renamed, the dependency edge points at a synonym. So the dependency walk resolves entities, not strings: exact thread join first, then authored supersession links, then the upstream's own stated name searched against the store — under a date gate that never loosens. This was the single largest cause of evolution questions silently failing before it was fixed.
The semantic route — needle vs haystack
When the entity is stable, the score shape decides between fetching a needle and gathering a haystack.
Exact recall — the needle. "Recite the exact error log I shared." One hit towers over the field, detected scale-invariantly (standard deviations above the pack, robust to the embedder's compressed scores). Engram returns a tight window instead of stuffing the context with sixty vaguely-similar drawers — but a window of five, not one. The goal is to guarantee the answer is present and trust the reader to pick it. Build for the reader's ceiling, not its floor.
Aggregation — the haystack, gathered by handle. "What are all my hobbies?" The trap: none of rock climbing, yoga, reading is semantically similar to "hobbies." A similarity search finds one facet and misses the rest. The fix is a handle the author can't fragment: a closed life-area vocabulary — about a dozen fixed areas (hobbies, health, finances, …), each fact tagged with one to three of them. The author classifies into a dropdown; it can't invent a label, so the handle is fragmentation-proof by construction. Retrieval gathers by set-membership on the area, not by the unreliable score. (Free-form topic slugs were measured first: facets scattered across ~2.5 slugs per store and recovery ceilinged at 50%. The closed vocabulary is the answer to a measured failure, not a stylistic preference.)
A small umbrella map handles questions that span areas ("what do I do in my free time" → hobbies + fitness + tastes), and every gather stays currency-total: an evolving entity collapses to its latest value, and a retracted entity doesn't enumerate at all — "list my subscriptions" must not list the cancelled one.
The substrate that makes it trivial
Notice what the read algorithms aren't doing: parsing prose, pattern-matching phrasings, guessing. They read typed fields the author wrote down — memory_shape for routing, depends_on for the dependency walk, consequent_value for cascade promotion, session_date for the trail order, area for the gather handle, thread_label for the trail itself. Each algorithm is short and almost obvious because the data was shaped right at write time. The cleverness lives in the substrate; the algorithms just read it.
Every field is authored from the conversation alone — never from the question, never from the answer key. That's the bar for the whole design: if a result only holds because of a lucky phrasing or a hand-tuned regex, it isn't real. If it holds because the type is right, it travels.
Agents reach all of this through the MCP surface — engram_recall for the one-shot answer path, engram_recall_thread for a dated trail, engram_gather for the wide sweep — and the same routing serves the MEME benchmark, where this architecture was proven.
A note on lineage
This decomposition tracks MEME's task taxonomy closely, and that's not a coincidence I'll pretend away: the benchmark was the map. I think it's a good map — close to an exhaustive enumeration of what can happen to a fact over time. A fact is stable or it changes; a change replaces a value, removes it, or propagates through something that depended on it; a question wants one fact, the set, or the history. Engram was circling half of that space before MEME existed in this repo — supersession and currency are April's decisions over discussion thesis under a new name — but the dependency axis (cascade, absence) is something the benchmark taught outright. What I've guarded against is the part that wouldn't travel: tuning to MEME's phrasings, its entities, its judge. The shapes are the claim; the thresholds inside them are still benchmark-taught and labeled as such, and the breadth runs — plus turning this machinery on Engram's own non-benchmark stores — are where the map gets tested against territory it didn't draw.
Scoring
Six multiplicative signals, one additive correction, one meta-signal that knows when to step back.
The scoring formula's value is defensive, not offensive — it protects against noise from low-authority, low-confidence memories.
Where scoring sits
Recall routes the question; scoring ranks the candidates. Every search across the drawer pool runs its merged Chroma + FTS5 candidate set through six multiplicative signals, one additive keyword correction, and a meta-signal — adaptive dampening — that disables the parts that would mislead when the pool has nothing to discriminate on. The honest framing is defensive: scoring keeps the wrong drawer from winning by accident; it doesn't conjure the right one out of nothing.
score = similarity
× salience ^ w_sal
× auth_factor (off by default in v2)
× conf_factor
× effective_type_mult (primary discriminator)
× diary_factor
final_score = score + keyword_boostThe signals, briefly. Similarity is the metric-aware cosine — the multiplicative base everything else scales (metric-aware is load-bearing; the May L2/cosine bug in the decisions log is why). Salience decays 2.5%/week and bumps on retrieval — the rate is a grid-search result — with intent weighting its exponent: debugging amplifies recency, planning dampens it. Authority is off by default since the authority-on-claim pivot; when opted in on multi-author stores it maps agent names to tiers, and dampening collapses it to neutral on single-author pools anyway. Confidence is a thin per-type default — that decisions and facts both carried 1.0 is exactly the bug that forced type × intent into existence as the primary discriminator: the deployment's type library against its six intents (the engineering vocabulary in multi-agent, the speech-act library in companion), each cell answering "how relevant is this kind-of-claim to this kind-of-question?" The diary penalty is a small carve-out that keeps personal notes from outranking canonical answers — the one signal that deliberately doesn't dampen.
[ memory_type × query_intent ]
v2 library · 10 types
| type ↓ intent → | planning | design | debugging | review | history | general |
|---|---|---|---|---|---|---|
| architecture | 1.40 | 1.30 | 0.60 | 1.00 | 1.00 | 1.00 |
| workflow | 1.20 | 1.10 | 0.80 | 1.00 | 1.00 | 1.00 |
| implementation | 1.00 | 0.80 | 1.00 | 1.00 | 1.20 | 1.00 |
| decision | 1.30 | 1.50 | 0.70 | 1.10 | 1.00 | 1.10 |
| bug | 0.80 | 0.70 | 1.50 | 1.20 | 1.00 | 1.00 |
| spike | 1.10 | 1.20 | 1.20 | 1.00 | 1.00 | 1.00 |
| retrospective | 1.00 | 0.90 | 1.00 | 1.50 | 1.30 | 1.00 |
| acceptance | 0.90 | 0.80 | 0.90 | 1.30 | 1.20 | 1.00 |
| directive | 1.50 | 1.20 | 0.90 | 1.10 | 1.00 | 1.20 |
| observation | 0.90 | 0.80 | 1.00 | 0.90 | 1.00 | 1.00 |
[ legacy library · pre-v2 ]
preserved for back-compat
| type | planning | design | debugging | review | history | general |
|---|---|---|---|---|---|---|
| fact | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| consequence | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| inference | 0.85 | 0.90 | 0.95 | 0.95 | 1.00 | 0.95 |
| opinion | 0.70 | 0.70 | 0.75 | 0.80 | 0.90 | 0.80 |
// legacy types remain writable; new authoring should prefer v2.
Adaptive dampening
This is the signal I'd point at if I only got one. Authority, confidence, and type × intent all pass through dampening before they multiply in:
damp = H(signal_values) / H_max
effective_factor = damp × raw_factor + (1 − damp) × 1.0H is the normalized entropy of that signal across the candidate set, and H_max is a schema property, not a tuning knob. A uniform pool collapses the factor to neutral; a diverse pool fires it at full strength. Add a memory type and dampening rescales deterministically — so if a benchmark regresses, the fix is a mechanism argument, never a dampening tweak.
The keyword side is the same temperament: FTS5 exact-match hits get a small post-scoring additive boost — deliberately not multiplied by metadata, which would compound bias. In validation it lifted Recall@1 from 14% to 23% by rescuing drawers whose distinctive phrasing semantic search was burying.
The override boundary
The honest limit, measured: scoring re-ranks the embedder's neighborhood and cannot rescue a candidate sitting more than ~1.7× below the top hit's similarity. The fix for a candidate outside that window isn't in scoring at all:
That's the coupling the whole system is built around — scoring sets the discrimination floor; authoring moves candidates into the neighborhood where scoring can do its job.
What scoring does and doesn't claim
The MEME results validate the system end-to-end — substrate, routing, scoring, and authoring together. What they deliberately don't isolate is the 6-signal formula's own contribution versus the routing and the substrate; on uniform-metadata pools dampening should make scoring a no-op, and that no-op is correct behavior. The dashboard's per-candidate breakdown exists for exactly this question, and isolating the formula on corpora I didn't author is on the validation roadmap. The framing stays defensive until it's done.
Benchmarks
MEME — the evolving-memory evaluation Engram's thesis was tested on. Plus the roadmap and the honest caveats.
The benchmark is a teacher, not a target. Every change has to be a genuine system lift — something that would survive MEME changing its judge, its answerer, or its phrasing.
The thesis test
MEME — Multi-entity & Evolving Memory Evaluation — is a public benchmark (reference implementation + dataset) for memory systems whose facts change, get deleted, and depend on each other over time. An episode is a series of conversation sessions about a person's life or a software project; entities evolve (a medication, a database choice), some get retracted, some rest on others. Six task types are scored: exact recall, tracking an entity's history, aggregating facets of a topic, deletion (don't recite a removed value), cascade (X depends on Y; Y changed and X's new value was declared — report it), and absence (Y changed and no new X was declared — X is now unknowable; say so).
No public benchmark targets Engram's actual claim more squarely. And the harness is honest by construction: every system gets the same held-constant shell — retrieve(question) → a fixed answering LLM → the same GPT-4o judge. A system controls exactly one thing: what context it surfaces in a single shot. No agentic drill-back, no second look.
The numbers
On the full 100-episode set, with the benchmark's standard configuration — gpt-4.1-mini as both the authoring and answering model, GPT-4o as judge, the same configuration the published baselines used:
The published reference results, against Engram's run on the same dataset, answerer, and judge:
| system | ER | Tr | Agg | Del | Cas | Abs | overall |
|---|---|---|---|---|---|---|---|
| Engram | 95 | 83 | 68 | 95 | 88 | 70 | 83.2 |
| MD-flat | 94 | 77 | 45 | 25 | 6 | 5 | 42 |
| Dense retrieval | 96 | 46 | 33 | 17 | 4 | 0 | 33 |
| Mem0 | 67 | 43 | 35 | 21 | 3 | 0 | 28 |
| BM25 | 100 | 16 | 5 | 27 | 2 | 0 | 25 |
| Karpathy Wiki | 11 | 27 | 18 | 3 | 1 | 2 | 10 |
| Graphiti | 3 | 4 | 1 | 9 | 2 | 1 | 3 |
The shape of that table is the thesis. On exact recall — the similarity-shaped task — Engram is at parity with the field; BM25 literally wins it. The separation is entirely on the state-management and dependency-reasoning tasks, where the MEME authors observe that published systems collapse (cascade averages 3% across them, absence 1%). Those are the tasks where the answer isn't in any retrieved text — it has to be derived from a typed, dated trail. That derivation is what the recall architecture does, and nothing in a chunk-and-embed pipeline has a place to do it.
Three qualifiers on the comparison, in fairness both directions. The baseline numbers are the benchmark's published results, not local re-runs. Engram's score uses MEME's real-pass accounting, which is stricter than the printed judge total (deletion/cascade/absence answers only count when the system demonstrably didn't know the answer before the change and did after; trivial passes are excluded). And the deepest one: Engram's recall architecture was developed with MEME as its test harness — that's what "teacher" means in practice — so this score demonstrates fit to the evolving-memory regime, not yet generalization beyond it. The two standing rules (changes must survive the judge, answerer, or phrasing changing; eval metadata can never reach authoring, asserted by a test) are the guardrails against tuning to the instance, and the breadth runs below are where the generalization claim actually gets tested.
The stronger-reader probe
One more run, deliberately not a field comparison: the same authored stores, re-read by gpt-5.5 instead of gpt-4.1-mini.
The headline lift is modest — and modest is the point. If a much stronger reader gained a lot, that would be a tell that Engram was surfacing noisy context and relying on the reader to rescue it. A +4.4 lift says the surfaced context is already legible to a mid-tier model — legibility is the architecture's job, done at write-time and derivation-time, not the reader's.
And look at where the lift lands. The mechanical columns barely move: exact recall, deletion, and cascade are tasks where the derivation is already done and rendered in the context — the reader transcribes, so reader capability is nearly irrelevant. The lift concentrates in aggregation (+10) and absence (+13) — the two tasks that inherently ask the reader for judgment: synthesize a set of facets, or commit to a calibrated "I'm not sure." A stronger reader collects exactly the headroom that belongs to the reader. The benchmark's golden-facts oracle closes the frame at 98.75% solvability — with perfect retrieval the remaining loss is the answerer's, so every miss is attributable to one side of the write/read split.
The progression
The campaign's own arc says where the lift came from: the first full-100 run scored 67.8%; typed dependency substrate, closed vocabularies, currency rendering, and the entity-resolving dependency walk took it to 83.2% in seven days of measured, one-variable-at-a-time iteration. Every variant ran as a labeled A/B on seeded episode draws; anything that couldn't survive the seed rotating didn't count.
Honest residuals
What the current number is not hiding:
- Absence sits at 70% by a deliberate trade: the authoring contract records only dependencies the user actually stated, so implied edges go unrecorded and their absence questions can't fire. Loosening the bar re-admits spurious edges; the fix under design keeps the bar and catches omissions in-session.
- Software-domain aggregation is the weak column. The closed life-area vocabulary covers personal-life facets; its project-world sibling (the "endeavor" taxonomy) is designed but not built, and free-form fallbacks measurably fragment.
- Single-question swings are noisy. The answerer flips on byte-identical contexts at a measured ±few-points band on the small task columns — every surprising delta gets autopsied per-flip before it's believed.
What's next
MEME is the sport Engram plays. The roadmap is breadth: LoCoMo, LongMemEval, and MemoryArena runs, to establish the floor alongside the peak — evidence that Engram stays competent in the sports it doesn't play, with a predictable floor on conversational-recall workloads, while being strong in the one it does.
Earlier validation
Before MEME, validation was component-level micro-evals (April–May 2026), and they still anchor specific mechanisms: the supersession eval (86.7% hit@1 vs 53.3% raw cosine, and the ~1.7× override boundary that scoping work made measurable), the HEAVY-SPLIT tool-surface change (53% → 97% signature compliance), and the companion-mode classification battery (92.4% strict / 98.5% defensible). MEME replaced them as the headline because it's external, adversarial to the whole pipeline at once, and scored by a judge I don't control.
Dashboard
The operator surface — same HTTP API as the MCP adapter, different face.
Operator and agent see the same store — exactly. The dashboard is a different face on the same HTTP API, not a separate semantic.
The dashboard is a React 18 + Vite + TanStack SPA mounted by the daemon at /dashboard/*, with types generated from the daemon's /openapi.json — so it and the MCP adapter cannot drift. Its value isn't operator-specific semantics; it's that some things are easier with eyes and a pointer: pattern-spotting across hundreds of drawers, iterating on an authoring prompt, watching an ingest job run.
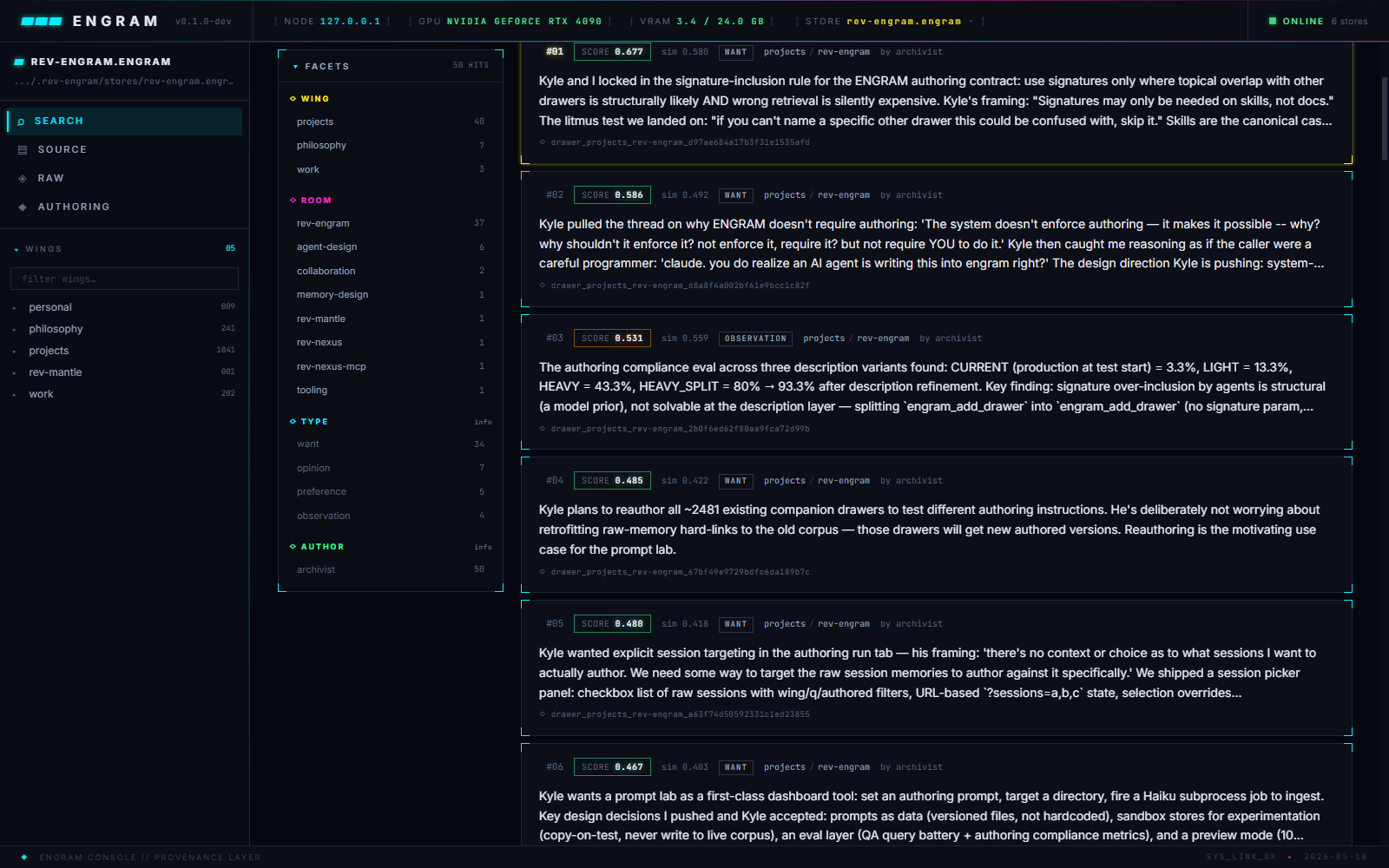
Search
The scoring formula's operator presentation: query, optional wing/room scope and intent, and a per-candidate breakdown showing which signals fired and which dampened to neutral. This is the screen where scoring's honest question gets investigated — whether the formula did real work on a given query, or the win was just embedder neighborhood.
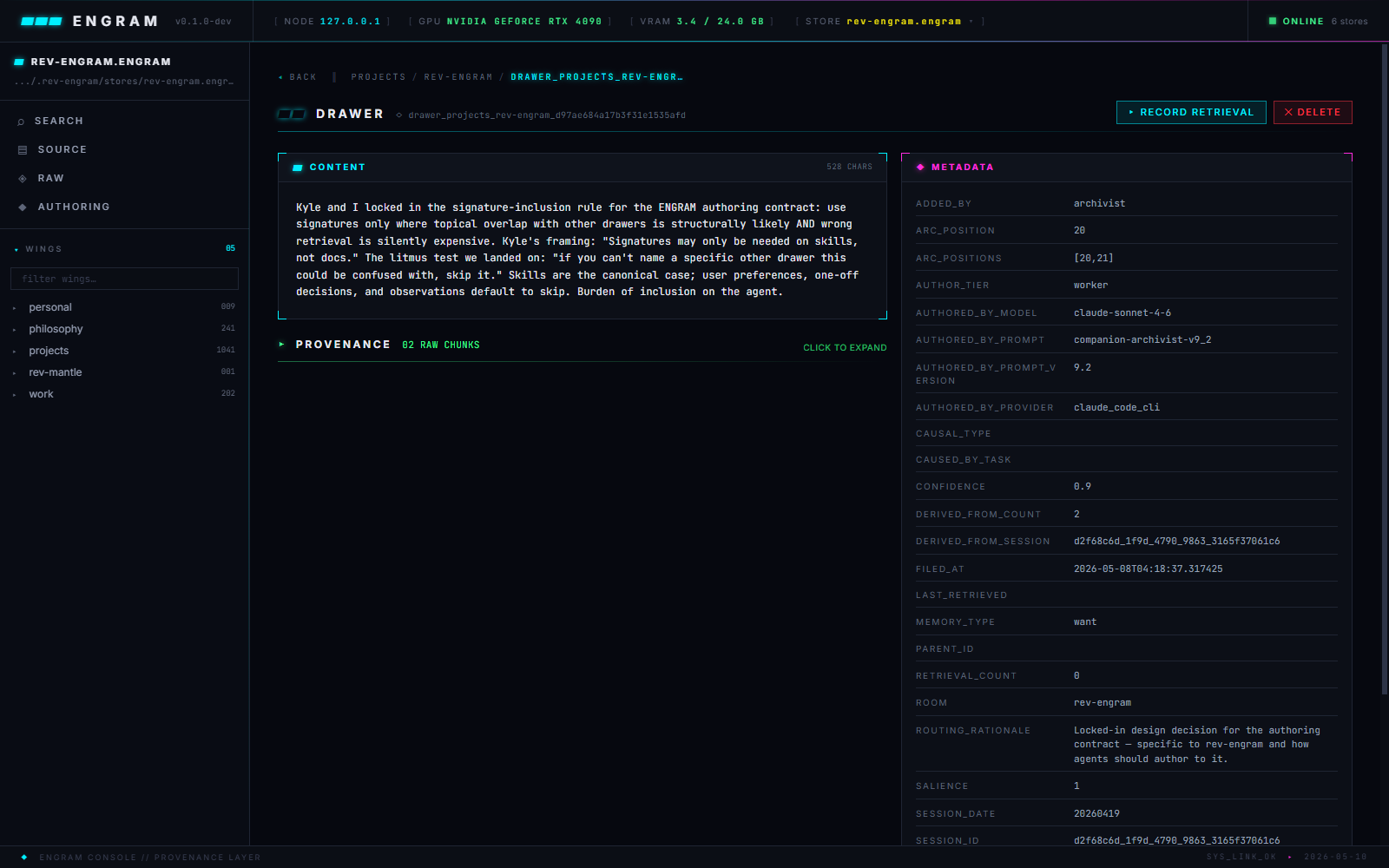
Drawer detail
Content, provenance log, and the full metadata sidebar — where authoring discipline is visible at a glance: signature, pin_status, memory_type, salience, derived_from_arcs. A threads browser sits alongside it, grouping drawers by thread_label into the dated trails the recall evolution route reads.
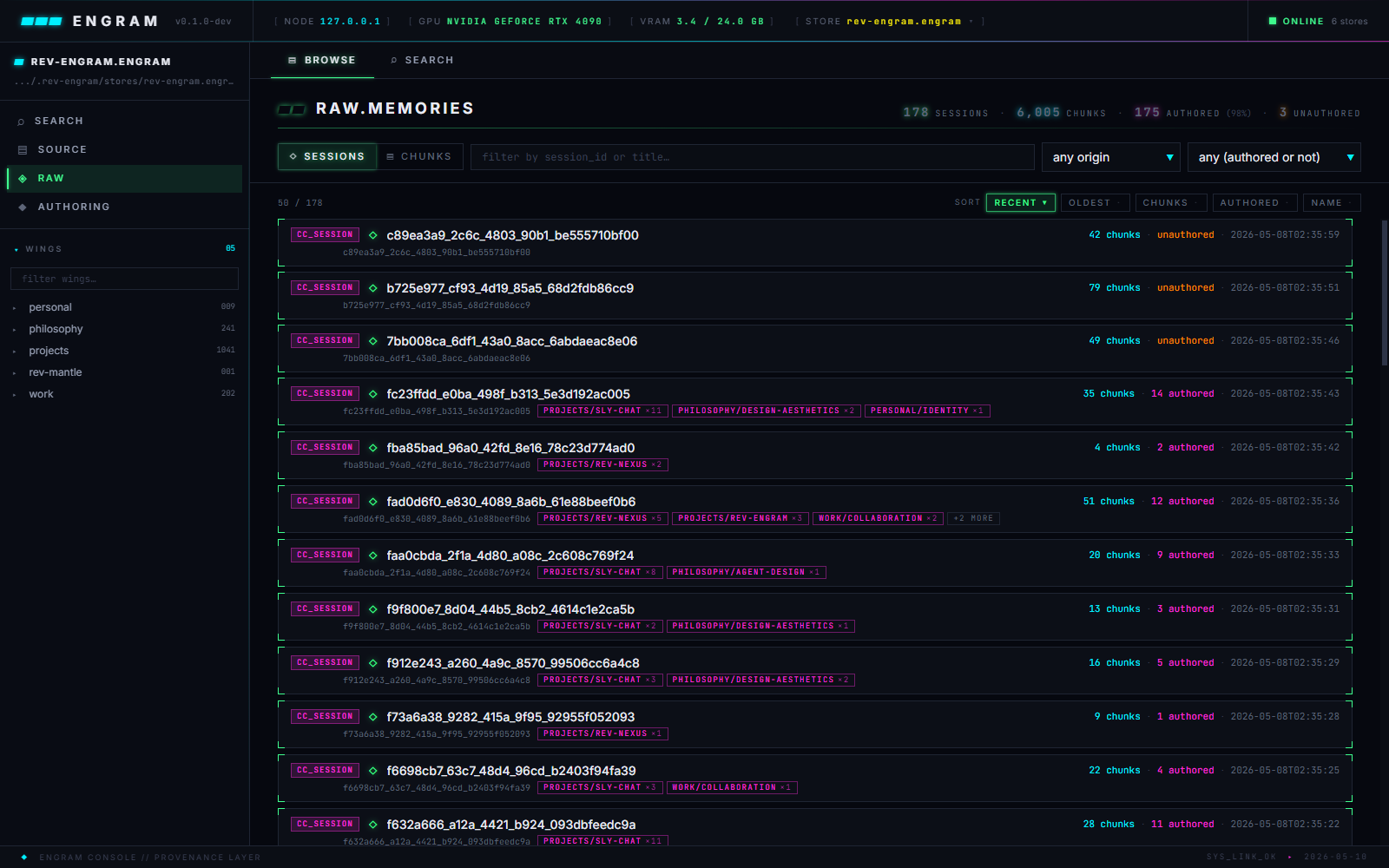
Raw
The unframed substrate, session-grouped, with origin chips and the count of drawers already authored from each session — plus a search toggle for similarity-only verbatim lookup.
Authoring corpus
The file manager for the first tier: files in <store>/_corpus/, foldered, each with a state badge — uploaded (○), ingested (◐), authored (●) — mapping to its position in the three-tier pipeline. Select files, hit ingest, and the job runner chunks them into raw memories and composes drawers via the configured invoker. Walkback lives here too: re-author a file after refining instructions, or delete downstream raw + drawers and start over.
Authoring instructions
The prompt lab — the dashboard's highest-leverage surface, because authoring is the system's highest-leverage discipline. Prompts live as versioned files; an operator iterates, smoke-tests against a single session, and only then promotes to production. A sibling provider tab picks model + reasoning effort + invoker; swapping providers is a config change, not a code change.
Everything the dashboard shows, the MCP adapter can reach; everything the adapter writes, the dashboard can browse. That's the discipline the architecture was built around — one HTTP API, three thin clients — and the dashboard is just the one with a face.
Methodology
How Engram gets validated — and how it actually got built.
I don't want to fake bench numbers. I really want to know what we have here.
Built with Claude as the guide
I held the vision and pushed back. Claude was the guide that executed against the constraints I set and surfaced findings — what broke, what passed, what reasoning it was relying on that I hadn't reviewed. Three disciplines made that produce a coherent system instead of a pile of plausible code: pull the thread (when something doesn't fit, follow it until it resolves — most pivots in the decisions log started as a thread that wouldn't tie off), prompt pedagogy (lead the model with "if X and Y, what does that imply about Z?" instead of overriding it), and vision first, goal second (if the goal pulls away from the vision, the goal moves). I caught Claude drifting from authority-supersession into temporal-supersession mid-session once — same vocabulary, different axis — and holding the vision while Claude executed is what kept the system from getting plausibly-off.
This isn't AI-built. It's AI-collaborated. The architecture, the pivots, and the discipline are mine; most of the routes through code are Claude's. Both layers are real, and the system only exists because both happened.
The validation surfaces
- External benchmark. The MEME campaign is the primary surface — an external dataset, a judge I don't control, and its own honesty tooling (replay before judging, paired per-episode A/Bs, rotated seeds, a fairness firewall with a test asserting eval metadata can't leak into authoring).
- Agent-as-QA. Spawn a fresh Claude session, frame it explicitly as evaluation, not task completion, and capture its friction as data — a fresh session has no investment in the build, so what trips it up is signal. The canonical run found a real companion-multiplier regression the unit tests missed, in under nine minutes for $1.55.
- The retrieval log. Append-only JSONL per store capturing every retrieval event crossing the ops boundary — queries logged, drawer text not. It answers the question a solo dev can't answer honestly without it: when a search returned drawers, how often did one actually get used?
- Three-layer pytest. 1,000+ tests split by what each layer can verify — library primitives, the daemon's HTTP contract, the MCP adapter. The split is the architectural claim: each layer catches a different class of regression.
- Dogfooding. Engram's own documentation once accumulated into exactly the noise the thesis warns about, and the recovery applied Engram's principles to Engram — a minimal authoritative current-state layer, discussion demoted out of the priming path.
It's literally my thesis, there's TOO MUCH context in here. I'm preloading you with context on things I don't even know the content of.
What we don't measure (yet)
MEME settled the big one: the system demonstrably beats similarity-shaped retrieval at task level, externally judged. Still open, and named: the 6-signal formula's isolated contribution on corpora I didn't author; the breadth runs (LoCoMo, LongMemEval, MemoryArena) that would turn "predictable floor outside the home sport" from roadmap into result; and companion-mode generalization beyond my own deployments. The framing stays defensive until those land.
Decisions
The pivot arc — reconstructed from Engram's own store, oldest first.
Every other section describes Engram as it runs today. This one is the history — reconstructed the way the rest of the project works: from Engram's own store. Dates in the first three eras are drawers' real session_dates, not commits (git would mislead — the repository came after the work was already underway). The final era is dated from the repo's own history; by then the work was committed as it happened. A decision log isn't a changelog: each entry named something the system started or stopped doing on purpose.
I. Foundations — the mid-April burst
Engram's shape was argued out in about two weeks. Almost everything load-bearing landed between April 15 and 21, much of it dogfooded in the very sessions that designed it.
The 6-signal scoring formula
◇ shippedThe earliest decision in the store: similarity × salience × authority × confidence × a per-type multiplier, over a merged Chroma + FTS5 candidate set. The motivating bug was concrete — decisions and facts both carried confidence 1.0, so confidence alone couldn't tell them apart. Provenance had to become a scoring input, not a metadata tag.
Adaptive dampening — signals earn their weight
◇ shippedA signal only bends the ranking when it actually discriminates: low diversity across the candidate set collapses that signal toward neutral. My framing at the time: a conditional prior — I believe authority matters here when the data supports that belief, otherwise I defer.
Decisions over discussion — the thesis, proven live
◇ shippedWhen two memories on the same topic compete, the authoritative one wins — regardless of freshness or query vocabulary. Proven in the act of designing it: mid-session, the conversation itself drifted from authority-supersession to recency, and I caught it — "This is the drift. This is the thesis being proven in real time in the discussion to solve it."
Vocabulary coupling — author and reader share an embedder
◇ shippedThe writing agent and the reading agent share an embedder by construction, so authoring word-choice is the retrieval lever. Authoring discipline becomes load-bearing from here on.
HEAVY-SPLIT tool surface
◇ shippedOne drawer-write tool became two — unsigned and signature-required — forcing the agent to commit before composing. Richer tool descriptions had lifted authoring compliance from 3.3% to 43.3% and plateaued there; the split took it to 93.3% fully-correct. The plateau was a structural model prior, not a wording problem — so the fix had to live in the shape of the tool surface.
Companion mode as a peer deployment
◇ shippedSingle-agent, 1:1 memory as a peer shape, not a fork: a compressed four-type speech-act library — want · preference · opinion · observation (I rejected seven: "Less is more here… we don't need to split hairs") — and narrative-assembly retrieval instead of single-best-answer. Same daemon, same scoring path; only the type matrix swaps.
Authority-on-claim, not author-tier
◇ shippedThe pivot from
author_tier × type × intenttotype × intent. Tiers become write-scope boundaries; authority comes from the kind of claim, not the claimant. Made a requirement because it keeps Engram architecture-agnostic — consumers don't need a tier registry to adopt it.Source ingestion as a structural boundary
◇ shipped"Source content is not memory — it's files." Code and docs get their own collection, their own similarity-only retrieval — the drawer pool cannot be polluted by code chunks because they live in a different pool. Sync reconciles by content hash.
Default embedder: Jina v5-small, in-process
◇ shippedSwap from Ollama-served
qwen3-embedding:8b(4096-dim, external daemon) to in-process Jina v5-small (1024-dim) — warm retrieval ~280ms → ~110ms, one runtime dependency gone. "qwen3 is a straight-up-worse-in-every-way situation." An opinion with a shelf life: the verdict was about 8B-served-by-Ollama, and the Qwen3 family gets the last word on 2026-06-05.
II. The daemon refactor — late April
The in-process era ended: every agent loading its own embedder, contending for the same Chroma lock. The refactor split the surface into one long-running daemon and N thin clients.
Store handles over module globals
◇ shippedThe monolithic
EngramServicegod-class gave way to aStorehandle plus operations as free functions inengram/ops/, with Pydantic models as the one source of truth across HTTP, MCP, and internal calls. Multi-store operation and per-operation testability fall straight out of it.Daemon as canonical implementation; clients as thin translators
◇ shippedFramed in Postgres terms: "the daemon is postgresd, the MCP adapter is postgres-mcp middleware, the dashboard is pgAdmin." One persistent daemon owns the embedder and the store registry; a stateless stdio adapter translates tool calls to HTTP; the dashboard SPA is served by the daemon itself. One process, one port, one bearer token, one auth flow.
Daemon v1 hardening — tiers, registry, audit
◇ shippedBearer tokens with
read/write/admintiers (localhost-only binding as the primary control),StoreRegistrypersistence with fail-open replay — and a formal post-refactor security audit that found real teeth:/dashboard/bootstrapwas handing out an admin token unauthenticated. Fixed alongside constant-time token compare and replay-path validation.Retire the legacy in-process stack
◇ shippedWith the daemon proven, the old surface was deleted, not deprecated — roughly 9,000 lines gone in one pass. The three-piece shape — library, daemon, thin adapter — becomes the product.
III. Authoring rebuild — early May
With the daemon shipped, attention moved to the highest-leverage surface: how raw conversation becomes framed, retrievable memory.
Wings = kind, rooms = identity
◇ shippedThe data model's meaning written down at the same level as the scoring formula: wings are kinds of memory, rooms are long-lived identities. The fix for a store that had sprouted thousands of wing/room pairs wasn't a count limit — it was naming the distinction so it survives across sessions.
Files as the durable first tier — the _corpus/ rename
◇ shipped_ingest_staging/becomes_corpus/, and the reframing is the decision: files stop being throwaway chunker input and become a durable, user-owned corpus. The three-tier shape locks here: file → raw memory → authored drawer, each a derivation of the one above.Whole-session authoring + arc provenance
◇ shippedAuthoring shifts from per-chunk and stateless to whole-session composition — every raw chunk from a session in one call, so the agent can group exchanges into coherent drawers. Each drawer carries
derived_from_arcs, so walkback stays possible at source granularity.
IV. The evolving-memory turn — late May into June
The May 8 session ended mid-investigation, on a bug. The fix landed the next morning — and the month that followed changed what Engram is: from a provenance-aware re-ranker into an evolving-memory engine with an external benchmark to prove it.
The L2 / cosine fix — similarity becomes metric-aware
◇ shippedThe HNSW index used L2 distance, but scoring computed the cosine conversion — so the best hits scored slightly negative and any positive score floor silently dropped everything. The fix is a dedicated metric-aware conversion, and the lesson stands: the long-standing
−0.3similarity floor was never embedder semantics — it was a workaround for this undiagnosed bug.Narrative threads — memory grows a time axis
◇ shippedDrawers gain a
thread_label— the stable slot an evolving value lives on — andengram_recall_threadreturns a dated trail instead of a ranked list. The first structural move from rank the candidates to read the history.MEME as the teacher — dependencies become authored claims
◇ shippedThe MEME benchmark enters as the external test of the thesis, under two standing rules: genuine lift, not score-chase (a change must survive the benchmark changing its judge, answerer, or phrasing) and a fairness firewall (eval metadata can never reach authoring; a test asserts it). The same day,
depends_onlands — the dependency between two facts, captured as a typed field the moment the user states it.Embedder: Jina → Qwen3-Embedding-0.6B
◇ shippedJina's non-commercial license was a dead end, and the new 0.6B Qwen3 release benchmarked at parity-or-better on Engram's workload. Apache-2.0, same 1024 dimensions, in-process — the Qwen3 family wins in the end at a thirteenth of the original's size. A migration CLI re-embeds old stores; a mismatch guard refuses to open a store against the wrong embedder.
One-shot recall in core — the three regimes
◇ shippedrecall_oneshotis promoted from benchmark adapter to core: one search, read the shape of the hits, route. The evolution route reads the dated trail and picks its regime — deletion suppresses, cascade promotes a pre-declared consequent, absence derives uncertainty. None of those states is stored; all are computed at read time.Closed vocabularies — handles that can't fragment
◇ shippedFree-form topic slugs were measured failing (facets scattered across ~2.5 labels per store; recovery ceilinged at 50%). The fix: the author classifies into a closed life-area vocabulary instead of inventing labels. The HEAVY-SPLIT lesson, generalized — when the agent's freedom compounds the wrong default, constrain the surface, not the prompt.
The full-100 — 67.8 → 83.2
◇ shippedThe campaign's headline run: the full 100-episode MEME set, standard configuration, real-pass accounting — 83.2%, from 67.8% at the campaign's start, against 42% for the strongest published system. The separation comes entirely from the dependency and state-management columns — exactly where the thesis said it would.
The edges
There's an order of magnitude more churn in the codebase than this page admits — test passes, renames, fixes that left semantics untouched. And the record begins 2026-04-15, the earliest decision the store holds, so the genuinely-earliest design is referenced inside it but not datable from it. The far edge is no longer a cliffhanger; it's a scoreboard with a roadmap attached.